1、现代数据库系统如何实现数据的独立性?数据库设计中,数据模式遵循的范式是越高越好么?(10 分)
现代数据库系统通过三级模式结构实现数据独立性,即:
- 外模式(用户视图)
- 概念模式(全局逻辑结构)
- 内模式(物理存储结构)
并通过两级映像实现数据独立性:
-
外模式 / 概念模式映像
实现逻辑数据独立性,即概念模式改变时,用户视图和应用程序不必修改。
-
概念模式 / 内模式映像
实现物理数据独立性,即物理存储结构改变时,逻辑结构和应用程序不必修改。
数据库设计中,数据模式遵循的范式不是越高越好。
高范式可以减少数据冗余,避免插入、删除和更新异常,但范式过高会导致表数量增多、查询连接复杂、系统性能下降。因此应根据具体应用场景在规范性与性能之间进行权衡。
2、某宾馆需要建立一个住房管理系统,需求分析结构如下:
① 一个房间有多个床位,每个房间有房间号(如 201、202 等)、收费标准、床位数目等信息;
② 客人信息包括身份证号码、姓名、性别和地址等信息;
③ 对每位客人的每次住宿,需记录其入住日期、退房日期和预付款信息。
根据需求分析,设计的关系数据模型如下:
房间(房间号,收费标准,床位数目)
客人(身份证号,姓名,性别,出生日期,地址)
住宿(房间号,身份证号,入住日期,退房日期,预付款额)
假设订房人即入住人,请给出上述三个关系模式存在的所有主键和外键。(外键 4 分,主键 8 分)
主键:
- 房间:主键为 房间号
- 客人:主键为 身份证号
- 住宿:主键为 (房间号, 身份证号, 入住日期)
外键:
- 住宿.房间号 → 房间(房间号)
- 住宿.身份证号 → 客人(身份证号)
3、针对上述应用场景下的三个关系模式,写出表达下列查询要求的 SQL 语句(必须用单条 SQL 语句表达):
(1) 用连接查询查找预定了编号为 210 号房的客人姓名;(6 分)
(2) 查询预定过所有房间的客人的姓名;(8 分)
(3) 查询 2016 年 1 月份只有一人预定的房间号及客人姓名;(8 分)
(4) 对累计订房次数超过 60 次的客人,查询每位客人单月预订房间的最大次数及该最大次数对应的年份与月份。(8 分)
(1) 参考答案:
SELECT 客人.姓名
FROM 客人, 住宿
WHERE 客人.身份证号 = 住宿.身份证号
AND 住宿.房间号 = 210;(2) 参考答案:
SELECT 姓名
FROM 客人
WHERE NOT EXISTS (
SELECT *
FROM 房间
WHERE NOT EXISTS (
SELECT *
FROM 住宿
WHERE 住宿.身份证号 = 客人.身份证号
AND 住宿.房间号 = 房间.房间号
)
);(3) 参考答案:
SELECT 房间号, 姓名
FROM 客人, 住宿
WHERE 客人.身份证号 = 住宿.身份证号
AND getYear(入住日期) = 2016
AND getMonth(入住日期) = 1
AND 房间号 IN (
SELECT 房间号
FROM 住宿
WHERE getYear(入住日期) = 2016
AND getMonth(入住日期) = 1
GROUP BY 房间号
HAVING COUNT(*) = 1
);(4) 参考答案:
SELECT 身份证号, 年份, 月份, MAX(月订房次数) AS 最大订房次数
FROM (
SELECT 身份证号,
getYear(入住日期) AS 年份,
getMonth(入住日期) AS 月份,
COUNT(*) AS 月订房次数
FROM 住宿
GROUP BY 身份证号, getYear(入住日期), getMonth(入住日期)
) AS T
WHERE 身份证号 IN (
SELECT 身份证号
FROM 住宿
GROUP BY 身份证号
HAVING COUNT(*) > 60
)
GROUP BY 身份证号, 年份, 月份;4、相对层次、网状数据库系统,查询优化对关系型数据库系统更为重要。这句话对么?为什么?(8 分)
该说法是正确的。
层次型和网状数据库系统采用导航式访问,访问路径由应用程序指定,数据库系统本身几乎不进行查询优化。
关系型数据库采用声明式查询语言,用户只描述”做什么”,不描述”怎么做”,由数据库系统自动选择执行路径,因此查询优化在关系型数据库系统中尤为重要。
5、从查询优化角度分析,为什么 SQL 查询 where 子句应尽量避免使用”OR”。(8 分)
OR 谓词构成析取条件,难以有效利用索引。通常需要分别计算各条件的结果集,再进行并集操作,并集开销较大;若 OR 中某一条件无法使用索引,整个查询可能退化为全表扫描,从而显著降低查询效率。
6、阅读下列说明,回答问题 (1)、(2)。假设两项业务对应的事务 T1、T2 与存款关系有关:
转账业务——T1(A,B,s),从账户 A 向账户 B 转 s 元;
计息业务——T2,对当前所有账户计算利息(即原金额为 X 元,计息后为 X×1.2)
(1) 若将计息业务设计为对单个账户分别计算利息,即 T2(A)、T2(B),这种方案是否正确?为什么?
该方案不正确。
计息业务应当基于数据库的一致性状态整体执行,若拆分为对单个账户分别计息,在并发执行时可能导致部分账户基于旧数据、部分账户基于新数据计息,从而破坏事务一致性。
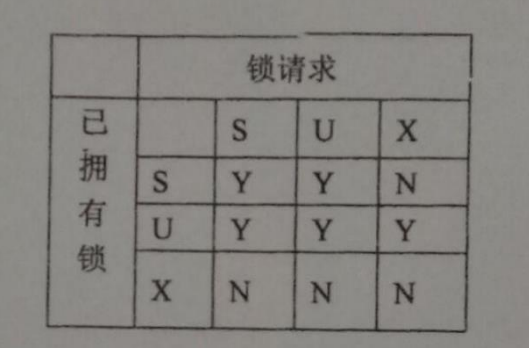
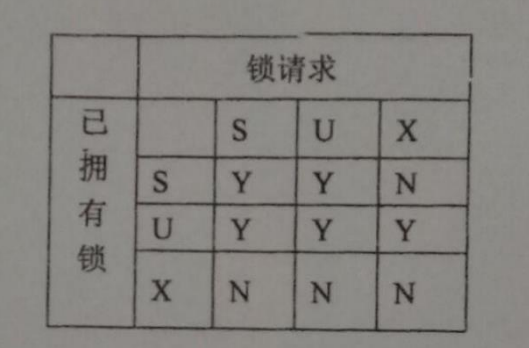
(2) 题设两个事务 T1 和 T2 的一个并发调度如下表所示,引入 (S,U,X) 锁(注意:相容矩阵如下图),若初始时 A=100,B=60,s=20,最终 A、B 结果如何?该并发调度正确与否?
给定并发调度表(原题)
T1(A,B,s) T2
----------------------------------------
Read(A)
A := A - s
Read(A)
Write(A) A := A * 1.2
Write(A)
Read(B)
Read(B)
B := B * 1.2
B := B + s
Write(B) Write(B)
执行结果计算
 正确性分析
正确性分析
- 本题引入了 U 锁,那么 Read-内存里改数据-write 整个过程就被定义成了 update
- !!!!!!!注意!!!!!!!本题中 SUX 相容矩阵和书上不一样,按照题目里给的来, 定注意仔细看!
T1(A,B,s) T2
----------------------------------------
① Read(A)
A := A - s
②Read(A)
③Write(A) A := A * 1.2
④⑦Write(A)
⑤Read(B)
⑧Read(B)
⑨B := B * 1.2
B := B + s
⑥Write(B) ⑩Write(B)
① T1 申请 A 的 U 锁,批准
-
T1
Read(A)=100 -
T1 计算:
A := A - s = 100 - 20 = 80(暂存在内存里)
② T2 申请 A 的 U 锁
-
A 上已有 T1 的 U,根据矩阵 U 与 U 相容(Y),批准
-
T2
Read(A)=100(注意:此时 T1 还没写回,所以读到原值 100) -
T2 计算:
A := A * 1.2 = 100 * 1.2 = 120(也先在内存里)
③ T1 申请 A 升级到 X 锁
-
A 上还有 T2 的 U,根据矩阵 已有 U,请求 X 为 Y,批准
-
T1
Write(A)=80(把 80 写回数据库) -
严格 2PL:T1 事务未结束,不释放锁,仍持有 A 的 X 锁
④ T2 申请 A 升级到 X 锁
-
此时 A 上有 T1 的 X,根据矩阵 已有 X,请求 X 为 N,不批准
-
T2 卡住等待(按你假设:被阻塞就不再往下执行)
⑤ T1 申请 B 的 U 锁,批准
-
T1
Read(B)=60 -
T1 计算:
B := B + s = 60 + 20 = 80
⑥ T1 申请 B 升级到 X 锁,允许(B 上无锁,当然允许)
-
T1
Write(B)=80 -
T1 结束(commit),释放所有锁:释放 A 的 X、B 的 X(以及内部的 U)
⑦ T2 终于获得 A 的 X 锁
-
注意:T2 早在②就把 A 的计息结果算成了 120(基于读到的 100)
-
现在获得 X 后执行:
Write(A)=120(把 T1 的 80 覆盖掉)
⑧ T2 申请 B 的 U 锁,批准
- T2
Read(B)=80(这是 T1 已经写回的 80)
⑨ T2 在内存修改
B := 80 * 1.2 = 96
⑩ T2 写入 B(需要升级到 X,然后写)
-
升级 X(B 上没人持 X),允许
-
Write(B)=96 -
T2 commit,释放锁
7、假设运行记录与数据库的存储磁盘有独立失效模式,介质失效恢复时,对运行记录中上一检查点以前的已提交事务应该 redo 否?为什么?(8 分)
介质失效后,应加载最近的后备副本,并利用运行记录中的后像进行 redo。
若检查点时间晚于后备副本生成时间,则对后备副本之后、检查点之前已经提交的事务,也应进行 redo,以保证数据库恢复到一致状态。
8、试在第 1 题的住宿关系表上定义一个触发器,实现以下功能:对每条 Insert 语句,若插入的记录没有退房日期,则回卷该操作。
参考答案:
CREATE TRIGGER check_checkout_date
BEFORE INSERT ON 住宿
FOR EACH ROW
BEGIN
IF NEW.退房日期 IS NULL THEN
ROLLBACK;
END IF;
END;